A month after Anthropic’s Claude Mythos announcement, most of the commentary is still focused on what AI can find. The harder question — and the one that will matter more over the next 18 months — is what happens after it finds something.
The coverage is tracking the wrong metric.
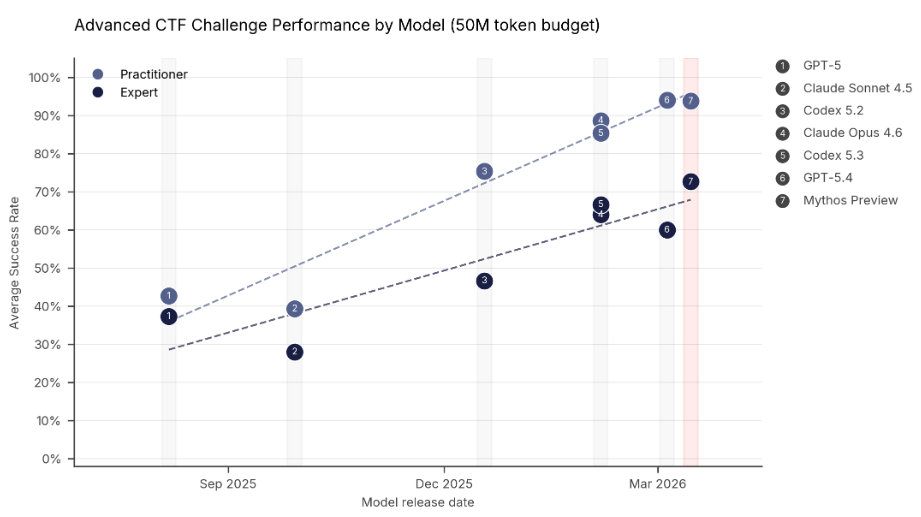
Performance on practitioner and expert level Capture the Flag tasks. Source: AI Security Institute
Discovery is mostly solved. Validation isn’t.
On April 7, Anthropic announced Claude Mythos Preview and Project Glasswing. The UK AI Security Institute evaluated Mythos on expert-level CTF tasks where no model could complete them at all before April 2025. Mythos succeeded 73% of the time. Anthropic’s own Frontier Red Team documentation shows Mythos chaining four browser vulnerabilities into a working exploit autonomously, and writing a remote code execution exploit for FreeBSD’s NFS server that grants root access to unauthenticated users.
That is real. But Mythos is gated to roughly 52 organizations through Project Glasswing and is not publicly available. For everyone else, the relevant signal is not Mythos specifically — it is what Mythos confirms about a trajectory that has been visible for at least 18 months.
XBOW reached #1 on HackerOne’s US leaderboard in mid-2025 by submitting roughly 1,060 vulnerability reports in three months — the first autonomous system to outperform human researchers at scale. AISLE was credited with discovering 13 of 14 OpenSSL CVEs across two coordinated releases in 2025. And AISLE’s post-Mythos analysis shows much of Mythos’s reasoning is recoverable by cheaper models once the relevant code paths are scoped.
The discovery side of the curve is bending fast. If that surprises you, you have not been paying attention. The bottleneck is moving downstream, and that is the part most teams are not ready for.
The validation crisis
HackerOne data puts the invalid rate on incoming bug bounty submissions at 60–80%. Their triage operation handles 4,000 reports per week with 45 in-house analysts. The 2025 SANS Detection and Response Survey found 73% of respondents identified false positives as a main challenge, up from 64% the year before.
Now layer agentic discovery on top of that. XBOW had to add a validator layer — automated checkers that verify whether a vulnerability actually exists — plus pre-submission human review, specifically to keep their false-positive rate low enough to maintain HackerOne reputation. The honest practitioner critique from Rawsec is worth reading: the public XBOW numbers reflect what passed internal triage, not what the AI initially produced. The volume of pre-triage findings is unknown but materially larger.
The post-Mythos environment makes this dynamic worse, not better. AI systems generate findings faster than human teams can validate them. The findings that need human judgment — exploitability in business context, reachability in production paths, severity recalibration — cannot be automated reliably yet. Engineering teams, already short on appsec capacity, now face a queue that grows faster than it shrinks.
Most practitioner commentary on Mythos has missed this because the narrative is dominated by discovery. But the interesting engineering problem right now is not how to generate more findings. It is what to do with the ones you have.
%%{init: {"theme": "base", "themeVariables": {"primaryColor": "#e8f4fd", "primaryBorderColor": "#3182ce", "secondaryColor": "#fde8e8", "tertiaryColor": "#fff9e6", "fontSize": "16px"}}}%%
flowchart TD
subgraph discovery["Discovery — machine speed"]
direction LR
d1["XBOW - Mythos - AISLE - autonomous scanners"]
d2["Agent exploit chains - multi-step, autonomous"]
d3["Static analysis + fuzzing pipelines"]
end
queue["Raw findings queue - 60–80% invalid — volume outpaces team capacity"]
subgraph validation["Validation — human speed"]
direction LR
v1["Is this real? - Hallucinated code path?"]
v2["Reachable in production? - Compensating controls?"]
v3["Severity in business context?- CVSS vs actual risk"]
end
roadmap["Prioritized remediation roadmap owned · dated · retest criteria"]
discovery --> queue
queue --> validation
validation --> roadmap
style discovery fill:#dbeafe,stroke:#3b82f6,color:#1e3a5f
style validation fill:#fee2e2,stroke:#ef4444,color:#7f1d1d
style queue fill:#fef9c3,stroke:#ca8a04,color:#713f12
style roadmap fill:#dcfce7,stroke:#16a34a,color:#14532d
The discovery side is accelerating. The validation side is not. Most Mythos commentary is focused on the left half of this diagram.
Three observations from the field
These are from engagements over the past six months. Not theory.
The “is this real” question is harder than it used to be
When a finding comes from a static analysis tool with a known false-positive profile, you triage it with established heuristics. When a finding comes from an AI agent that constructed a plausible exploit chain, the heuristics break down. The exploit chain may be technically valid but unreachable in your specific production architecture. It may be valid and reachable but irrelevant because of compensating controls. It may be invalid because the agent hallucinated a code path that does not exist. Each of these requires manual verification against your actual system — and the three cases look identical from the outside.
Severity ranking in business context is doing more work than it used to
A critical vulnerability in an internal tool used by three people may matter less than a moderate one in your customer-facing API. Generic CVSS does not capture this. AI-generated findings tend to arrive with severity labels that are technically defensible but operationally noisy — they reflect the tool vendor’s generic risk model, not your deployment. Reranking against your actual business context is still a human task, and I have seen it absorb more analyst time than the initial triage did.
A list of 200 findings is not actionable. A prioritized roadmap of 30 findings with clear ownership, deadlines, and retest criteria is. The translation step — from finding to roadmap — is where most teams lose the most value when they over-rely on AI-generated output.
What to prioritize in the next 90 days
If you are building or operating an AI-powered product, three things are worth doing before Q3 regardless of whether you have Glasswing access.
Establish a validation methodology before the findings arrive. It does not need to be elaborate — three questions are enough: how do you decide a finding is real, how do you score severity in your business context, and how do you route it to remediation. If you are already running an AI-augmented appsec pipeline, this is what closes the loop. If you are not, build it before your customer or auditor asks for evidence of it.
Map your reachability surface. For an agentic system, this means more than network reachability. Which parts of your agent’s tool surface are actually accessible from untrusted input? Which memory stores can be poisoned? Which RAG retrieval paths could surface manipulated content? The OWASP Agentic Top 10 (ASI01–ASI10) is a reasonable starting frame. The question is which categories matter most for your specific deployment.
Decouple discovery from prioritization. It is tempting to let the same tool that generates findings also rank them. Do not. Discovery is a machine-speed problem now. Prioritization is a business-context problem and will stay human-led for the foreseeable future. If your pipeline collapses these into one step, you inherit the prioritization choices the tool’s vendor made — which were not made with your organization’s risk profile in mind.
The Mythos coverage will keep running for another few weeks and then shift to whatever Anthropic announces next. What will not shift is the queue. Teams that build a validation practice this quarter will be in a different position by Q4 than teams that spent the same time improving their discovery pipeline.
References
- Anthropic Frontier Red Team, Claude Mythos Preview technical evaluation, April 2026: red.anthropic.com
- Anthropic, Project Glasswing, April 2026: anthropic.com/glasswing
- UK AI Security Institute, Our evaluation of Claude Mythos Preview’s cyber capabilities, April 2026: aisi.gov.uk
- AISLE, AI Cybersecurity After Mythos: The Jagged Frontier, April 2026: aisle.com/blog
- HackerOne, Internal vs Expert Triage: Why Your Triage Model Matters, February 2026: hackerone.com/blog
- Rawsec, About the hype around XBOW: blog.raw.pm
The Security Lab Newsletter
This post is the article. The newsletter is the lab.
Subscribers get what doesn't fit in a post: the full attack code with annotated results, the measurement methodology behind the numbers, and the week's thread — where I work through a technique or incident across several days of testing rather than a single draft. The RAG poisoning work, the MCP CVE analysis, the red-teaming patterns — all of it started as a newsletter thread before it became a post. One email per week. No sponsored content. Unsubscribe any time.
Join the lab — it's free Already subscribed? Browse the back-issues →