“I read the OWASP Agentic Top 10. I understood the risks. And I still had no idea whether my agents were locked down.”
That was my problem. I could nod at the framework and still not answer the one question that actually matters: where do we stand right now?
The OWASP Agentic Top 10 tells you what the risks are. It does not tell you where you specifically stand. And it certainly does not tell you which three gaps are bleeding in your stack.
So I built something to fill that gap.
Agent Security Scorecard is a free, 12-minute self-assessment that scores your organization’s agentic AI security posture across five domains. Every question maps directly to a specific ASI control from the OWASP Agentic Top 10.
No signup required. No data stored. All scoring runs in your browser.
Try it here: https://scorecard.aminrj.com/
What it measures
The assessment covers five domains, each mapped to specific ASI controls from the OWASP Agentic Top 10.
Agent inventory and governance (ASI10)
Do you know your agents exist, who owns them, and is there a gate before they ship?
Without a live inventory, every downstream control is guesswork. You cannot scope permissions, assign ownership, or detect rogue agents on systems you do not know exist. This is the number one gap that security leaders cite.
Identity, access, and least agency (ASI02, ASI03)
Do agents have their own scoped identity, and are their permissions limited to what they actually need?
Over-provisioned agents are the primary vector for tool misuse. The autonomy permission paradox makes this tempting to defer, but every unused permission is an attack surface. When an agent uses a shared account and misbehaves, you cannot tell what it did or revoke just its access.
Is external content treated as untrusted? Can your agent’s memory be poisoned across sessions?
Agents cannot reliably separate instructions from data. A poisoned email, PDF, or RAG document can silently hijack the agent’s goal with zero user visibility. Persistent memory is a silent injection vector, because a poisoned entry from session N can redirect behavior in session N plus 100.
Execution and supply chain safety (ASI04, ASI05, ASI07)
Is agent-generated code sandboxed? Are third-party tools and MCP servers vetted and pinned?
Agent-generated code running with host privileges is a one-step path from prompt injection to full host compromise. 2026 saw the first agent-skill registry poisoned at scale and SSRF-vulnerable MCP servers found in the wild. An unpinned tool update is an automatic supply chain attack vector.
Detection, response, and containment (ASI08, ASI09, ASI10)
Can you see, replay, and stop agent misbehavior?
Cascading failures and rogue agents are invisible until they detonate. If you cannot replay the decision chain, you cannot fix the root cause. A compromised agent that takes two hours to stop has two hours to exfiltrate data, send emails, or cascade failures.
How scoring works
Each question uses a 0 to 3 maturity scale:
- 0 Absent. No control in place.
- 1 Ad hoc. Done inconsistently, no standard.
- 2 Defined. Standardized and documented.
- 3 Managed. Enforced, monitored, verified.
- N/A Not applicable (counts as 0 for scoring, tracked separately).
Your domain score is the mean of four answers, normalized to 0 to 100. Your global score is the mean of all five domains.
The screenshot below shows the full methodology breakdown that powers the assessment.
The result is not just a number. You get:
- A named archetype (Lopsided Fortress, Blind Operator, Methodical Builder)
- A radar chart showing where you are weak and where you are strong
- Your top three risks, ranked by severity and gap, each with a concrete first action
- A 30-day remediation roadmap, sequenced by impact
The screenshot below shows the scoring methodology detail that powers all of this.
Why the shape matters more than the score
A global score of 48 out of 100 could mean two very different things.
One team has 48 across every domain. They are uneven but not catastrophically weak anywhere.
Another team has Cognition at 83 and Identity at 17. The average is the same. The posture is fundamentally different.
That is why the archetype is derived from the shape of your five domain scores, not the global average. A team with one domain at 17 and another at 83 fires “Lopsided Fortress.” Not balanced. Not well-positioned. The label has to be honest.
The five archetypes you might get
The assessment assigns you a named archetype based on your score shape. Here are the ones most teams land in:
The Lopsided Fortress
You have hardened the sophisticated risks while leaving a basic one wide open. Your weakest domain undoes the work in your strongest.
Flying Blind
Agents are in production with little agent-specific security. This is the highest urgency band. Start with identity and containment.
The Blind Operator
You have controls, but little visibility into what agents do and no fast way to stop them. You would miss a quiet compromise.
The Optimistic Adopter
Moving fast on capability, light on the brakes. Your cognition defenses are ahead of your identity and containment controls.
The Resilient Operator
Enforced least agency, real auditability, tested containment. Agents are treated as production infrastructure.
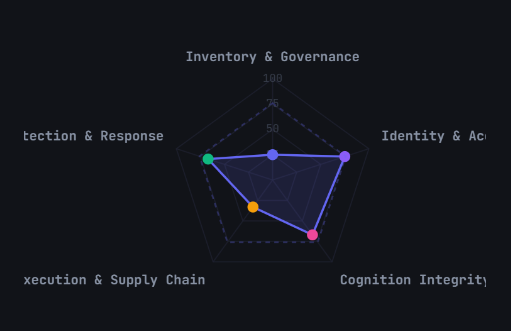
The radar chart: your posture at a glance
The radar chart is the single most useful output of the assessment. Each axis represents one domain. The dashed ring is the Resilient target (76+). The gap between your shape and the ring is where the story lives.
A perfect pentagon touching the outer ring means you are resilient across every dimension. A shape with one deep indentation tells you exactly where to focus. The visual makes the abstract concrete.
What most teams miss
I keep running into the same pattern. The most common gap is not prompt injection. It is identity.
Teams spend hours hardening their LLM prompts and forget that every agent running with shared credentials and broad permissions is a walking privilege escalation. A compromised agent with a shared service account does not just leak data. It becomes the attacker.
The second most common gap is containment. You can have the best controls in the world, but if it takes you hours to stop a rogue agent, those controls only delay the damage.
Try it
The assessment takes 12 minutes. The results are instant.
https://scorecard.aminrj.com/
The full PDF report with your complete remediation roadmap is available after the assessment. It is free. No strings attached.
If you work on agentic AI security, I would love your feedback. Which questions feel off? What gaps do you think are missing?
Immediate action items:
If you are deploying AI agents today, take these steps to secure your environment:
- Build a live inventory of every agent running in production. Name, purpose, owner, and what APIs it can call.
- Give your highest-privilege agent its own scoped identity and rotate any shared credentials it uses.
- Define your top five high-impact actions and add a mandatory confirmation step to each.
- Set a 90-day rotation schedule for all agent credentials as a floor toward just-in-time credentials.
- Time yourself: starting now, how long does it take to completely halt your highest-risk agent? Target is under five minutes.
The Security Lab Newsletter
This post is the article. The newsletter is the lab.
Subscribers get what doesn't fit in a post: the full attack code with annotated results, the measurement methodology behind the numbers, and the week's thread — where I work through a technique or incident across several days of testing rather than a single draft. The RAG poisoning work, the MCP CVE analysis, the red-teaming patterns — all of it started as a newsletter thread before it became a post. One email per week. No sponsored content. Unsubscribe any time.
Join the lab — it's free Already subscribed? Browse the back-issues →